
セキュリティリスク0!機密データも扱えるローカルAI

AIを業務に使いたい!しかしWebのAIサービスでは情報漏洩リスクに不安があるので秘匿性の高い情報の扱いは難しいのが現状。
その解になりうるのがローカルAIです!
Web版に比べるとマイナーですが、ローカルAIの情報もかなりあります!どれが良いか比較調査を開始。
| モデル名 | 開発元 | サイズ (例: パラメータ数/MoE) | 主な特徴・強み | 日本語性能 | 推奨用途 |
| Llama 3.1 | Meta | 8B, 70B, etc. | オープンソース界の標準。研究用途から実務まで幅広く利用される。コミュニティが大きく拡張性が高い。 | 良 | 汎用的なタスク、研究、高度な解析 |
| Mistral / Mixtral | Mistral AI | 7B, MoE 8x22B (Mixtral) | 軽量・高速で高い性能を両立。MoEモデルはリソース効率が良い。企業導入実績多数。 | 良〜優 | アプリケーションへの組み込み、軽量RAG、高速応答が必要なタスク |
| Gemma 3 | 2B, 9B, 27B, etc. | Google製。最新モデルは日本語性能が大幅向上し、小型サイズでも高性能。モバイル/組込機器にも強い。 | 優 | 軽量環境での利用、モバイルアプリ、教育・補助推論 | |
| Qwen 2 | Alibaba Cloud | 0.5B, 7B, 32B, etc. | 多言語対応に強く、特にアジア言語(日本語・中国語)での性能が高い。思考能力も向上。 | 優 | 多言語チャット、RAG、アジア市場での利用 |
| Phi-4 | Microsoft | 14B (Medium) | 超軽量ながら高い推論能力。学習教材や組込機器への最適化が進んでいる。 | 優 | 超軽量環境、教育用途、限定的な推論タスク |
| ELYZA-jp | ELYZA (日本) | 7B, 13B, etc. | 日本語特化の高性能モデル。国内での実績があり、日本語での自然な応答と安定性が強み。 | 優 | 日本語でのコンテンツ生成、企業内ナレッジ検索 |
性能面ではDeepseekやQwen (Alibaba) も良さそうだが、中国製は怖い。。。(本当にセキュリティリスクがない?)
できるだけ高性能なものがいいが、必要スペックとの相談もあり、画像認識にも使いたい、となるとなかなか選択肢が狭まってきますがありました!
Windows環境でOllama+gemma3+Docker+Open Web UIで実現可能です!
ローカルAI導入
それでは、実際にローカルAI環境を構築する具体的な手順を解説します。
1. 環境構築
必要なもの:
- Windows 10以降
- Docker Desktop (Docker Engineがインストールされます)
- Ollama (ローカルAIプラットフォーム)
- Open Web UI (画像添付も含むGUI環境実現)
- Google gemma3 モデル
手順:
- Docker Desktopのインストールと起動: Docker Desktopをダウンロードし、指示に従ってインストールと起動を行います。
- Ollamaのインストール: Ollamaの公式サイト (https://ollama.com/) から Windows 版をダウンロードし、指示に従ってインストールします。 インストール後、コマンドプロンプトで
ollama --versionと入力し、バージョン情報が表示されれば成功です。 - Open Web UIのセットアップ: DockerでOpen Web UIを指定すると必要なデータは導入されます。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main - gemma3モデルのダウンロード: Ollamaを使ってgemma3モデルをダウンロードします。
ollama pull gemma3 - Open Web UIの起動: Open Web UIの起動スクリプトを実行し、WebブラウザでLocalhost:3000にアクセスします。
起動しました!見た目は某AIのUIとそっくり。
ブラウザ上で動きますがアドレスはLocalhostで、もちろんインターネット環境がなくても動きます。
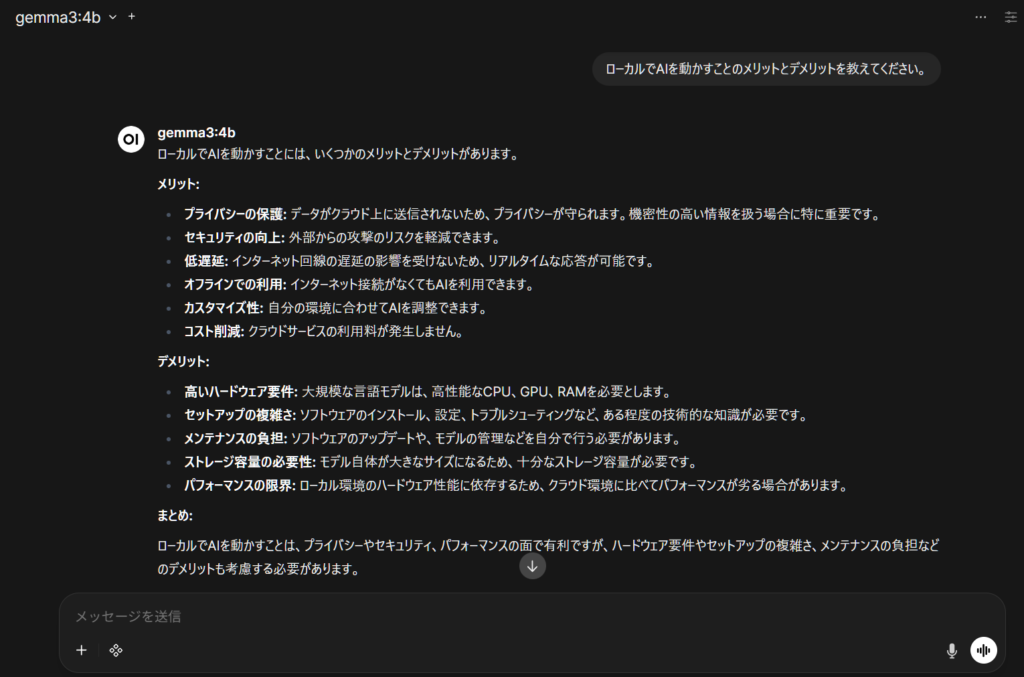
WebのAIサービスと使い方はほぼ同じです。
が、事前調査のとおりやはりレスポンスが悪く、上記の質問で回答しだすまでに18秒かかりました。
ローカルAIの特徴の一つがパラメータ調整が細かくできることです。(Web版でもAPI利用なら詳細設定可能)
カスタマイズ要素が多く、調整次第で好みの回答に寄せることができます。
今後起動する際は、以下だけなのでターミナルは必要ありません。
- Docker Desktop 起動
- Ollamaを起動
- ブラウザでlocalhost:3000にアクセス
※Docker、Ollamaを自動起動にしておけば、PC再起動後もなんの操作もなく使えますが、アイドル時でもそこそこのリソースを消費するので、必要な時だけ起動でいいかもしれません、これは各人の環境に依ります。
特にDockerはアイドル時でもメモリ1G程度は消費します。Ollamaの方は200MBほどです。
2. 必要なスペックの目安
- CPU: 6コア以上
- メモリ: 16GB以上(gemma3のモデルサイズや画像サイズによって変動します)
- ストレージ: 50GB以上(モデルファイルや一時ファイル用)
- GPU: (推奨) NVIDIA GeForce RTX 3060以上 (gemma3の推論速度を大幅に向上)
3. ローカルAIの特徴
- セキュリティ: データが外部に送信されないため、情報漏洩リスクを大幅に軽減できます。
- カスタマイズ性: 独自のデータセットでモデルをファインチューニングすることで、特定の業務に最適化できます。
- オフライン環境での運用: インターネット環境がなくても利用可能です。
- コスト: 運用コストは、サーバー費用や電気代などが該当します。
業務用AIとしての利用へ
個人のWindows機での検証でしたが、もちろんLinuxへも構築可能で、自社の内部データにアクセスできるAIサーバを構築し、セキュアな環境で動く貴社専用のAIサーバとして使えます!
特徴的な部分はベクトルDBでAIが参照するパラメータを管理します。

脳にあたるAIモデル層ではGemma3以外にも用途に合わせて換装は簡単にできます。新モデルへの対応も容易です。
見積作成や、請求処理、図面認識等、機密性の高いデータでもAIを活用することができ、業務の仕方を根底から変えるソリューションの可能性を秘めています。
性能について
Web経由で使えるChatGPT、Claudeなどに比べると回答の精度やレスポンス等では見劣りします。
理由はローカル環境のハードウェアスペックを考慮した量子化の影響もありますが、ハードウェアの差、パラメータ数(GPT4は1兆超えでローカルの20倍近く)、画像解析ではビジョンエンコーダー、解像度、トークン数制限等、様々な差異があります。
| 項目 | ローカルAI | Web版AI(ChatGPT/Claude/Gemini等) |
|---|---|---|
| モデルサイズ | 7B~70B程度 (70億~700億パラメータ) | GPT-4: 推定1.76兆パラメータ GPT-4o: 推定200B(効率化) Claude 3.5 Sonnet: 推定175B ※パラメータ数≠性能の高さだが大きな要因の一つ。 |
| 処理速度 | 小型モデル(7-13B): 数十トークン/秒 大型モデル(70B): 数トークン/秒 | GPT-4oは平均320ミリ秒(0.32秒)で応答 圧倒的に高速 |
| ハードウェア (ユーザー側) | 必須 • 7-13Bモデル: RTX 3060 12GB×2台程度(8-10万円) • 70Bモデル: RTX 4090 24GB(20-30万円)または複数GPU • 電気代: RTX 4090×2で月6,300円程度 | 不要 ブラウザがあれば利用可能 追加ハードウェア費用ゼロ |
| ハードウェア (提供側) | - | 超大規模 • GPT-4の学習には25,000個のNVIDIA A100 GPUを使用し約3ヶ月 • Meta Platformsは35万個のH100を購入予定 • MicrosoftとOpenAIは15兆円規模のAIデータセンター「スターゲイト」を計画中 • 数万~数十万個のGPUを並列稼働 |
| 推論品質 | 量子化による精度低下あり 小型モデルは複雑なタスクに限界 ベンチマークスコアはWeb版の1/2~1/3程度 | 最高品質 最先端の大規模モデルを使用 継続的に改善 上記ベンチマークで実証済みの高性能 |
| コスト | 初期投資: 内製での開発なら無料 電気代: 月数千円 運用・保守コスト別途 | 無料版あり 有料版: 月2,000-3,000円程度 API利用: 従量課金 |
| プライバシー | 完全にローカルで処理 データ流出リスクなし 機密情報に最適 | データがクラウドに送信される エンタープライズ契約で保護強化 |
| 利用可能なモデル | オープンソースモデルのみ (LLaMA、Mistral、Gemma等) 性能は限定的 | GPT-5、Claude Sonnet 4.5、Opus 4.1、Gemini 2.5 Pro など 最先端モデルを常に利用可能 |
| 適した用途 | • 機密情報の処理 • オフライン環境 • 研究・実験 • コスト削減(大量処理時) | • ビジネス全般 • 高度な分析・推論 • コーディング支援 • 最新情報が必要なタスク • 高品質な回答が必要 |
セキュリティ面ではオフライン稼働でローカルAIは100%安全と言えますが、Web版に比べ性能が落ちるので、パラメータ調整で各業務に最適な設定を組み補完する必要があります。
実用性についてはどういった業務をするか、データ量、安定した回答を得れるか等、検証が必要です。
まとめ
今回紹介した環境の構築なら1、2時間程度です。
セキュリティリスクから解放されて、業務効率を飛躍的に向上させる、ローカルAIの可能性をぜひ体験してください。
業務利用向けAIサーバのご相談は弊社HP(https://kiseeeen.co.jp)のお問合せからご相談ください。

